| Variable | B | SE_B | Beta | T | Sig_T |
|---|---|---|---|---|---|
| ALCOHOLTAXES | 1595.33990 | 380.76236 | 0.33367 | 4.19000 | 0.00010 |
| BELOWPOVERTYLINE | 4.65875 | 2.74999 | 0.15941 | 1.69400 | 0.09430 |
| COPRATIO | -1.72003 | 1.97365 | -0.06510 | -0.87100 | 0.38620 |
| PERSONSWITHDIPLOMA | 3.78480 | 3.84462 | 0.11740 | 0.98400 | 0.32800 |
| FEMALEHEADED | 0.16999 | 0.43491 | 0.02303 | 0.39100 | 0.69700 |
| HETEROGENEITY | 41.59058 | 25.20594 | 0.12895 | 1.65000 | 0.10310 |
| NETMIGRATION | 2.95424 | 1.08834 | 0.23224 | 2.71400 | 0.00820 |
| NOT2PARENTS | 83.28531 | 23.98275 | 0.33217 | 3.47300 | 0.00090 |
| PERSONSPERMILE | 139.62194 | 72.31688 | 0.16876 | 1.93100 | 0.05730 |
| PERCENTYOUNGMALES | -207.83213 | 193.87303 | -0.08147 | -1.07200 | 0.28710 |
| Constant | -977.27280 | 374.18150 | NA | -2.61200 | 0.01080 |
Minnesota Crime: Patterns Over Time and Across COVID
A Capstone Project for the Department of Math & Statistics
William Hamilton Borer Seabloom
Advised by Dr. Tyler George
Cornell College
Mar 3 2026
Abstract
In this paper, a 1998 study examining the sociological factors that impact crime across Minnesota counties is revisited. The original study’s parameters are extended from 1998 to the present and analyzed across two five-year periods before and after the COVID-19 pandemic. A clear spike in crime during COVID has been noted in previous literature, and this study examines whether traditional sociological predictors of crime changed both during COVID and over the longer period from 1998 to the present. The analysis employs the same core techniques used in the original study, including correlation analysis and OLS regression, and adds LASSO regression and structural break tests to assess how the relationships between crime and its determinants evolved over time.
Consistent with previous literature, a clear increase in crime is initially observed during the COVID period. Additionally, graphical analysis reveals several significant correlations between classic predictors and crime, as well as apparent shifts in these relationships during the COVID-19 pandemic. However, once these relationships are formally modeled using OLS regression, the interaction terms and direct effects associated with COVID become statistically insignificant, leaving only a small subset of the original predictors with meaningful explanatory power. While these remaining variables reflect some changes from the original 1998 study, they also indicate continuity in key determinants of crime. Notably, the inclusion of an indicator variable for counties containing tribal reservations emerges as a meaningful addition to the previous paper, with both its main effect and its interaction with net migration showing statistical significance. Median household income and population density also remain significant predictors of crime.
Overall, these findings suggest that while crime levels increased during the COVID period, the underlying sociological relationships driving crime across Minnesota counties remained largely stable. At the same time, the results highlight an evolution in the importance of certain predictors since the 1998 study, particularly the role of reservations and migration, which expand upon the original findings regarding the factors influencing county-level crime.
Introduction
In 1998, J. Mark Norman and Donald E. Arwood published a paper titled “A Social Disorganization Theory of County Crime Rates in Minnesota,” describing how the many different sociological measures of a society’s organization and control affect the crime rates in a community. These factors were measured across Minnesota counties and included factors such as education, wages, population density, and police presence. Recently, beginning during early 2020, the COVID-19 pandemic changed many factors of our society and disrupted many dimensions of social life. As discussed by Boman and Gallupe (2020), one of these many impacts was on crime rates, especially in relation to the more serious violent crimes analyzed in Norman and Arwood’s (1998) study. This raises an important question: Across Minnesota counties, how have the relationships between crime and its determinants changed over time, particularly in response to the COVID-19 pandemic?
The main goal of this research is to build on Norman and Arwood’s 1998 study by not only redoing the analysis with recent data but also looking at how these relationships have changed due to the COVID-19 pandemic. With crime and its prevention being a focal point of our world, and COVID changing many key parts of our society, it is important to reevaluate how typical sociological factors believed to have been related to crime could have shifted during the COVID-19 pandemic. The state of these relationships today is also important in the future prediction/prevention of crime.
To investigate the potential changes in the relationship between crime and its determinants, the study will compare crime counts from the FBI’s Crime Data Explorer with demographic and socioeconomic indicators drawn from the U.S. Census five-year county-level estimates. The analysis operationalizes crime rates as the number of Part 1 index offenses (homicide, burglary, robbery, aggravated assault, rape, larceny, motor vehicle theft, and arson) per county, normalized by population, and will include all 87 Minnesota counties. This definition of crime aligns with Norman and Arwood’s earlier work (Norman & Arwood, 1998) while also building on the more serious offenses that Boman and Gallupe (2020) identified as trending upward during the COVID-19 pandemic. Differences in crime rates, averaged across the five-year periods before and after the onset of the pandemic, will be examined to assess whether structural changes occurred. These differences will be evaluated through statistical modeling of both the pre and post-pandemic county-level data, as well as models estimating changes over time.
Literature Review
This project is informed by several key sources: Norman and Arwood (1998), James and Logan (2008), and Boman and Gallupe (2020). Together, these works provide a foundation for understanding the sociological determinants of crime, the limitations of available data, and the unique disruptions brought about by the COVID-19 pandemic.
Norman and Arwood’s 1998 study analyzed the relationship between crime rates and a variety of sociological measures at the county level in Minnesota. Their findings demonstrated that among a variety of traditional sociological indicators of crime, only these variables—alcohol consumption proxied by the county’s alcohol tax revenue, net migration in and out of the county, and households missing one or both parents—were significantly related to crime in Minnesota counties at the .05 level. (Norman & Arwood, 1998)
This work provides the methodological and theoretical foundation for the present project. While their study focused on the sociological context of the late 20th century, this research builds upon their approach by incorporating data up to the 2024 ACS 5 estimates and examining how these relationships may have shifted due to the COVID-19 pandemic.
While this study aims to replicate the factors studied in Norman and Arwood’s original study (1998), there are some key differences in the analyses. Comparing the variables used in each study, both crime rates are a 5-year average of Part 1 index crimes retrieved from the FBI’s crime reports. To measure household income levels, the study includes the median income, the percentage of the population below $5000 income, and below the poverty line. Both studies draw from the U.S Census’s 5-year ACS estimates. The same is done for the measures of heterogeneity, net migration, households with less than two parents, the percent of the population made up of young males, and the percent of the population with a high school diploma or greater. In the original study, population density is stated to come from the Census’s estimates, but due to a lack of availability, it is determined in this study to be the population of the county divided by the area of the county in m2. The final explanatory variable used in their study, revenue from taxes on alcohol sales, comes from the Minnesota Department of Revenue website and is also averaged across 5-year periods. Having mostly the same source data as Norman and Arwood’s (1998) original study, a general comparison to their original 1998 study is still possible, with the understanding of the real as well as potential changes in the data collection and reporting.
In order to track some of these changes, James and Logan’s report (2008) provides an overview of how the FBI collects and reports crime statistics, detailing the methodologies, limitations, and potential sources of bias within the Uniform Crime Reporting (UCR) database (James & Logan, 2008). Their report highlights challenges such as underreporting, changes in reporting practices, and differences in local enforcement priorities. James and Logan state that underreporting in the FBI crime data is a large problem, with systematic errors produced from the way that the data is collected (James & Logan, 2008). This bias stems from the fact that the only crimes the FBI reports are ones that the police have reported to them, and police officers are only aware of citizen-reported crimes, leading to two large sources of underreporting. Changes in reporting practices also affect this data, especially for the arson and rape counts. The way that rape was defined in this data changed in 2013 to remove the requirement of it being ‘forcible’, increasing the counts of this crime around this period as local law enforcement agencies changed their definition.
Furthermore, in any one instance of multiple crimes being committed, e.g., a break-in and homicide, only the homicide will be reported as it is the more severe of the two crimes. This leads to additional underreporting of less ‘severe’ crimes frequently committed in tandem with more ‘severe’ crimes. The one exception to this rule is arson, which is counted on top of any crime it is committed with. However, arson counts are only recorded if it can be proven that the fire was willfully set, meaning that it is difficult to actually prove and eventually report arson as an offense.
All of these insights are crucial for interpreting the results of this project, as they remind us that observed patterns in county-level crime rates may partly reflect variation in data quality or reporting practices rather than actual changes in criminal activity. By incorporating this perspective, this study can more carefully interpret both the limitations and strengths of using FBI crime statistics in the context of this paper’s results.
Boman and Gallupe’s (2020) research examines the effects of the COVID-19 pandemic on crime trends, with special attention to how crime patterns shifted during periods of widespread social disruption. They found that while many types of crime declined during the pandemic, homicide and other serious violent crimes rose due to young people (primarily males) being put in positions where they were in close proximity to partners or family members and further from their friends. This change in social structures led to less time spent with friends in situations where smaller crimes, such as vandalism, are often committed. They also hypothesized that this was due to a lack of normal outlets and these potentially minor offenders being moved into a situation where they have a much greater chance of committing a violent crime against their partners or family members.
Their findings suggest that structural shocks, such as a global pandemic, can have separate effects on different categories of crime. This study directly informs the paper, as it investigates whether similar shifts occurred in Minnesota counties, mainly the increased prevalence of violent crime relative to overall crime rates, as well as a potential shift in the predictability of crime after the pandemic.
Taken together, these works establish the intellectual groundwork for this project. Norman and Arwood (1998) demonstrate how sociological indicators can be systematically linked to crime rates at the county level. James and Logan’s 2008 report provides guidance on the interpretation of crime statistics, ensuring that my analysis acknowledges the methodological challenges of working with FBI data. Finally, Boman and Gallupe (2020) highlight the COVID-19 pandemic as a significant structural event that reshaped crime in the United States, motivating the inclusion of a temporal comparison between pre and post-pandemic trends in Minnesota. Building on these sources, my study aims to contribute by both replicating and extending prior methods to assess whether longstanding sociological-crime relationships have been altered by the COVID-19 pandemic.
Research Questions
Consistent with the findings of Norman and Arwood (1998), we expect that prior to the COVID-19 pandemic, county-level crime rates will be positively associated with indicators of social disorganization, particularly higher net migration rates, greater proportions of households missing one or both parents, and higher levels of alcohol consumption proxied by county alcohol tax revenue. In contrast, more traditional socioeconomic indicators such as median household income, educational attainment, and population density are expected to exhibit weak or statistically insignificant relationships with crime in the pre-pandemic period, as is found in earlier work.
The central hypothesis of this study is that COVID represents a structural shift in the relationship between crime and its sociological determinants. Specifically, the magnitude and significance of these relationships differ between the pre-pandemic and post-pandemic periods across Minnesota counties. From Jake Boman and Owen Gallupe (2020), this study further hypothesizes that post-pandemic crime patterns and violent crime are more strongly associated with indicators of family structure and demographic composition, such as the proportion of young males and family disruption, reflecting shifts in routine activities and social proximity during periods of social restriction.
Acknowledging the limitations of crime data highlighted by Nathan James and Wayne Logan (2008) as well as those acknowledged in Norman and Arwood’s (1998) study, this study hypothesizes that observed changes in crime rates will vary across offense types and counties in ways that reflect not only true changes in criminal behavior but also differences in reporting practices and data quality. As a result, observed changes in the modeled relationships between crime and its determinants should be interpreted as reflecting the combination of social disruption and institutional variation rather than as being due to criminal activity alone.
Data Description
The data being used in this study consists of two main parts: FBI crime and officer reports, as well as U.S Census Bureau county-level ACS 5-year estimates. A collection of other sources was used to supplement and summarize these main sources as well. All of the data and code for this project are publicly available in this GitHub repository (William Borer Seabloom, 2026) to document the process of this research. Any graphs, tables, and results discussed in this paper can be replicated by following the steps detailed in the repository.
To start, the FBI’s counts of crimes and officers were scraped from their website at a monthly level across all police agencies in Minnesota. As discussed in the literature review, James, Nathan, and Logan Rishard (2008) highlight the intricacies to be aware of when using the FBI crime data to draw real-world conclusions. Next, using the data from the National Law Enforcement Telecommunication System Originating Agency Identifier (NLETS ORI) directory (National Law Enforcement Telecommunications System, 1981), the local police agency data were mapped onto counties. As this data is a scanned PDF document,Optical Character Recognition (OCR) was used to convert the data into machine-readable text. This process does have some flaws due to the poor quality of the scan; a best effort was made to correct the minimal problems introduced into the data through this process. Additionally, as can be seen in the NLETS ORI directory, some police agencies that operate federally or across the whole state cannot be tracked by county and are therefore left out of the crime counts.
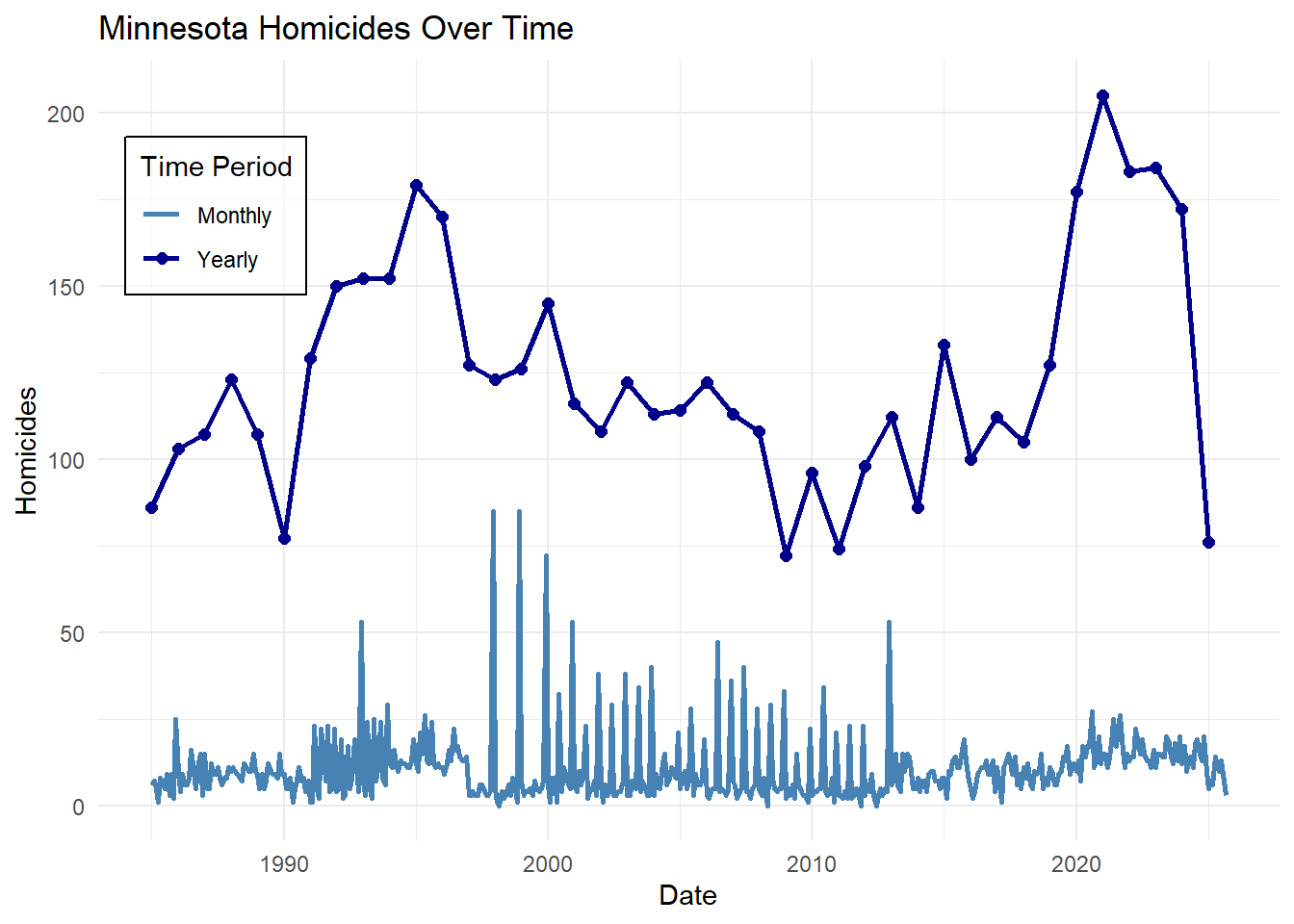
Above, a brief look at the monthly/yearly plot of homicides over time shows the issues in the data that are present across all of the FBI’s monthly crime data. The most obvious of these are the December peaks, as many police departments report the whole year of crime in December. This lasted from 1998 to 2013, when the FBI again changed how it receives and collects records. James and Logan’s 2008 report details many of the previous shifts in crime data collection and reporting as well. However, grouping the crime data into years removes the month-to-month reporting problems. It will allow for more direct comparison to the Census estimates.
Alcohol sales tax information was retrieved from the Minnesota Department of Revenue’s website. While this data is lacking some documentation, a general overview of collection and reporting is available at the Minnesota Department of Revenue’s website (Minnesota Department of Revenue, n.d.). There are two main inaccuracies cited: the first being that, as the gross sales data is not used in calculating taxes, it is under less scrutiny than other data, and accuracy cannot be guaranteed; the second being that there are potential errors in location reporting for businesses with more than one location. For the first issue, this study is using the taxes collected on liquor sales, which are closely examined for accuracy. Additionally, while any incorrect location reporting could affect the results directly, it is stated to be only a negligible number of businesses.
Using the liquor gross receipts tax (at 2.5%) information provided from the years 2015-2019, a pre COVID 5-year average was obtained. The Minnesota Department of Revenue’s data for 2024, however, had not yet been released, so a value for 2024 was imputed through a naive continuation of the 2023 adjusted value. This method seems best due to the unpredictable change in slope after 2020, seen below. Further, methods such as linear or LOESS models become unreliable due to the large outlier and sharp change in slope.
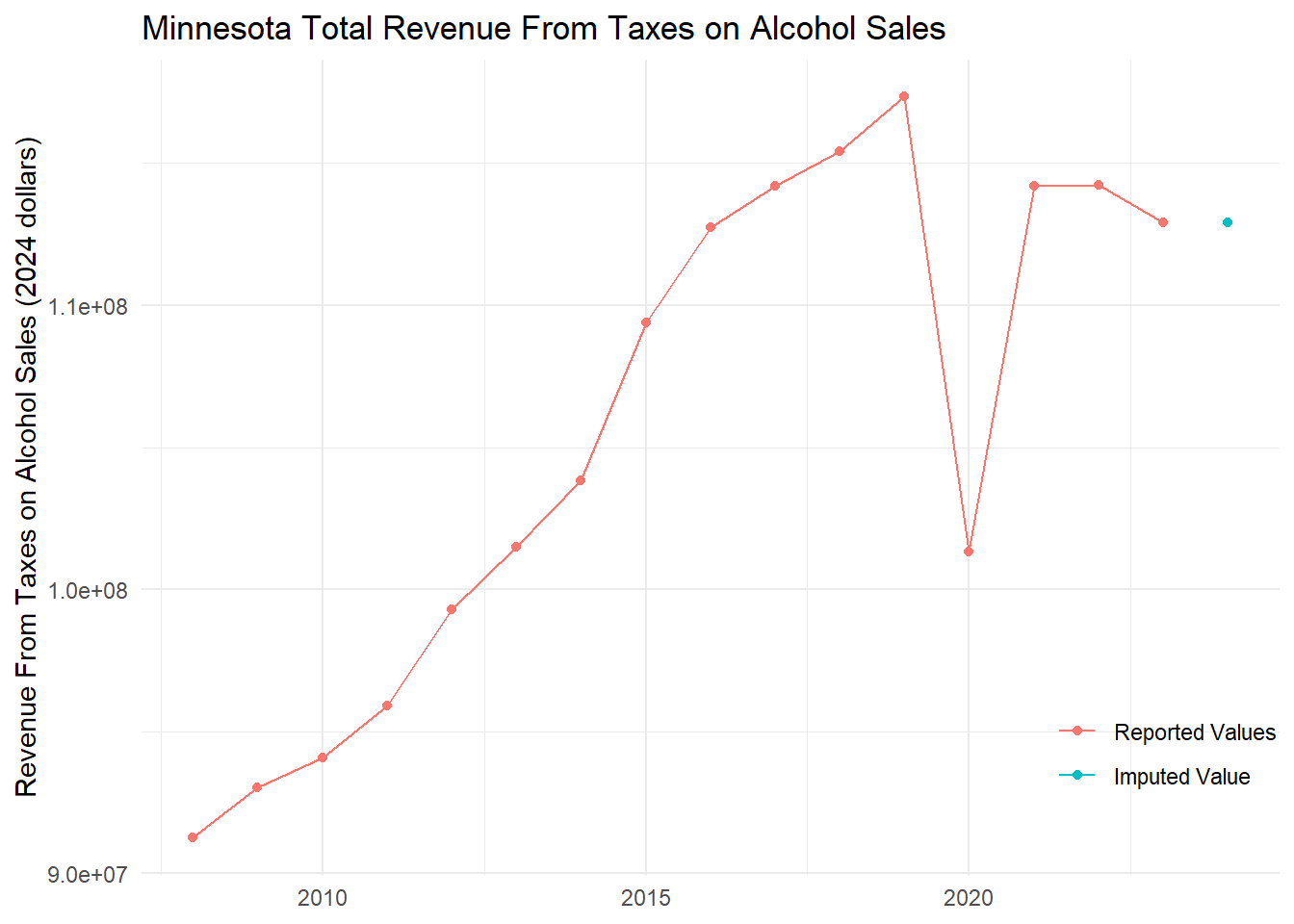
With this data now organized and graphed above, the clear positive trend in the revenue from alcohol sales taxes can now be seen up until COVID. This then dips sharply during COVID and sees a clear structural shift afterwards. These trends, at least after COVID, follow the common narrative seen in studies such as the 2024 National Survey on Drug Use and Health (Substance Abuse and Mental Health Services Administration, 2025) and the Minnesota Department of Health (Minnesota Department of Health, n.d.). These reports suggest that alcohol use by adults and minors has decreased or stayed the same in recent years and had a slight uptick during COVID. The drop in sales during COVID could, however, represent a problem with taxes as a proxy, as all in-person stores saw declines in consumerism during the pandemic.
Census Summarization
County-level 5-year estimates (ACS5) for the demographic variables of interest during the years 2015-2019 and 2020-2024 were then obtained from the U.S Census Bureau through the tidyCensus package. These estimates have their own problems, such as sampling and response bias (U.S. Census Bureau, 2025). The data from the U.S Census have multiple subtleties to be aware of, notably that every county is only available in 5-year average estimates and that these numbers are estimates based on a sample of the population. However, the 5-year averaging is not a problem in our case, as we want to examine structural changes resulting from the COVID-19 pandemic, and an average across 5 years will be able to represent that. The sampling and response biases, generated from who is sampled and who chooses to respond to a poll, will have to be addressed in the final interpretation of the results as a potential source of bias.
The dependent variable of interest, crime rate, is calculated by summing a 5-year average of all Part 1 index crimes collected from the FBI and dividing it by the total population estimate from the Census. The available demographic variables (officers per 1,000 people, median household income, the percent of households with less than $5000 income, the percent of people with a high school or greater degree, the percent of children missing parents, the percent of non-Caucasian residents, the percent young males, persons per household, persons per m2, and per capita net migration) used in Norman and Arwood’s 1998 study (Norman & Arwood, 1998) were then calculated using a variety of Census estimates.
The final data being used for modeling contains two rows for each of the 87 Minnesota counties representing the pre and post COVID periods, with 5-year average estimates for 2015-2019 and 2020-2024, respectively. The variables used in Norman and Arwood’s 1998 study (Norman & Arwood, 1998) will be tested in their effects on crime rates before and after to address the question of: how have the relationships between crime and its determinants changed over time, particularly in response to the COVID-19 pandemic?
Research Findings
Using this data, a few graphical representations of crime rates can help to better understand the nature of the data before modeling.
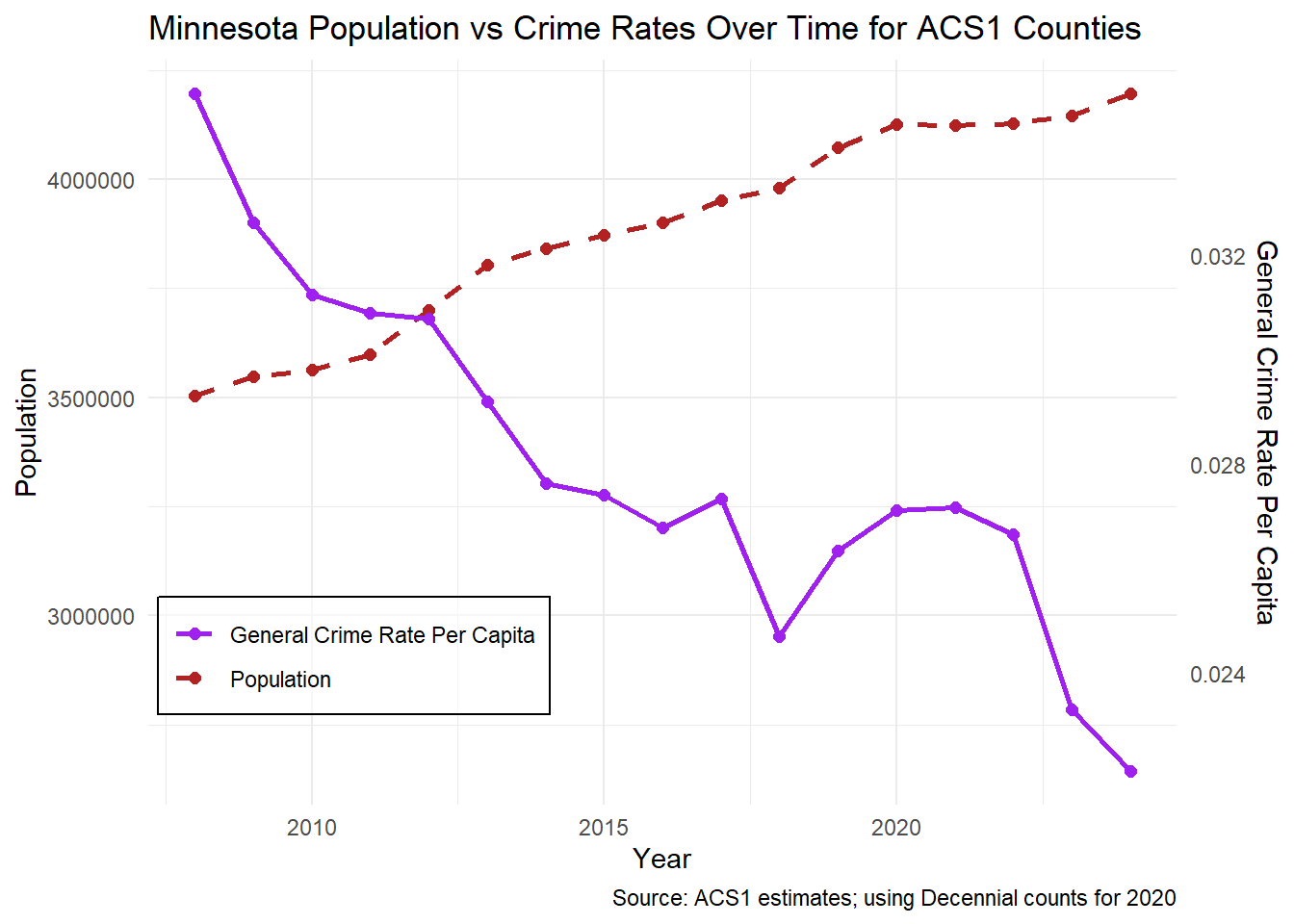
Using ACS 1 year estimates of population, a yearly plot of crime rates and population reveals a consistent downward trend in crime rates per capita, dropping with a steeper slope than the increase in population. This pattern suggests that crime rates have been declining over time. However, consistent with the predictions in the study by Boman, J.H., Gallupe, O (2020), there is a local peak of crime in 2020 and 2021 during the pandemic lockdown. Interestingly, even before the pandemic, there was still a sharp uptick in crime rates in 2019, suggesting other factors at play as well. Following this deviation, crime rates declined again by 2023, resuming the pre-pandemic trend. This indicates that the pandemic period represents a temporary disturbance rather than a lasting structural shift in Minnesota crime trends.
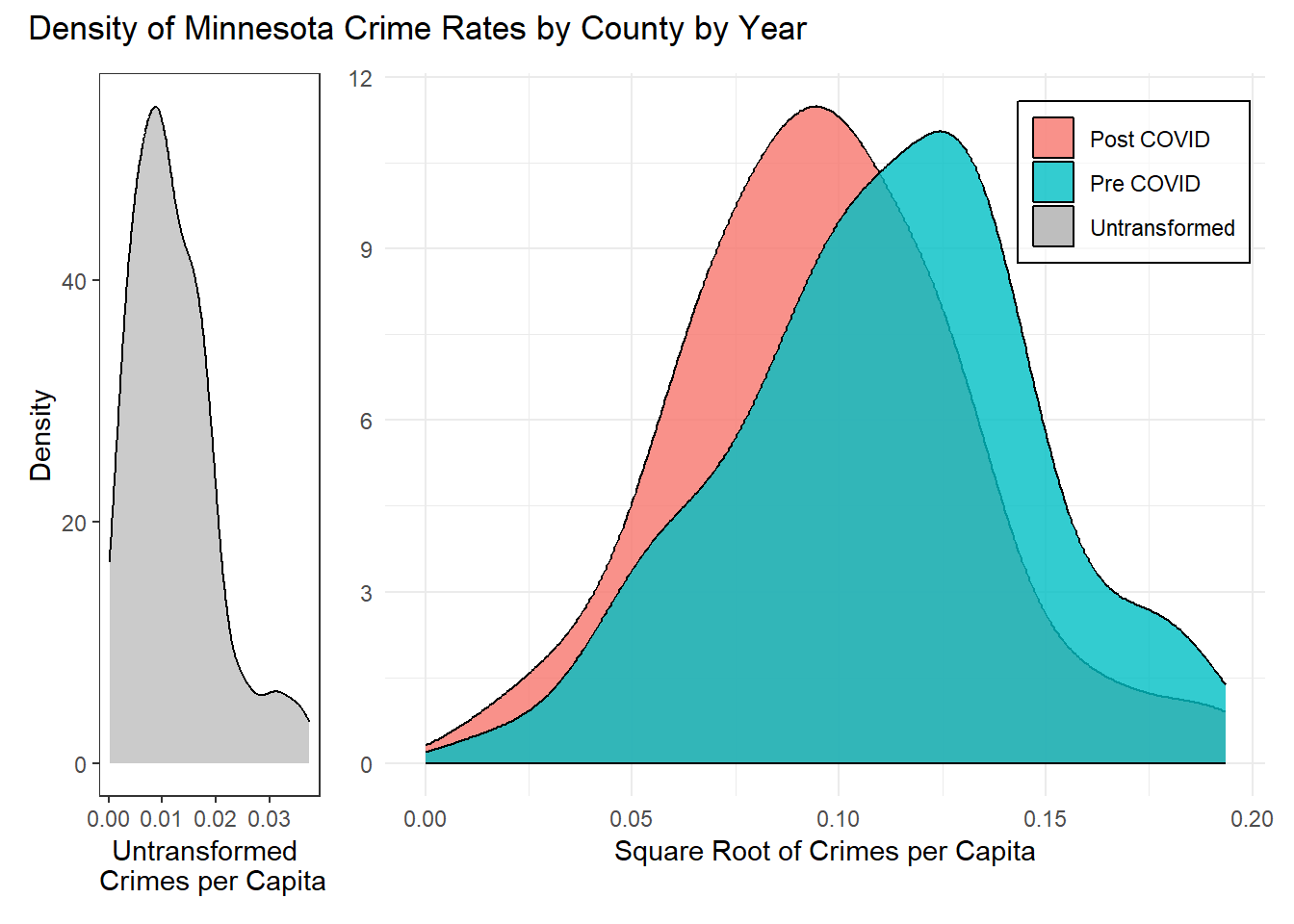
Looking at the general distribution of crime rates, there is a clear lack of normality due to the right skew. However, after a square root transformation, at least in the post-COVID values, we see an approximately normal distribution. This transformation will be used throughout the rest of the modeling process to stabilize the variance of the response. However, the pre-COVID distribution remains slightly left skewed but not dramatically. The shape does not meaningfully change post COVID, but there is a clear drop in crime rates able to be seen. This plot demonstrates again the dropping crime rates post COVID as well as a potential shift in the general distribution.
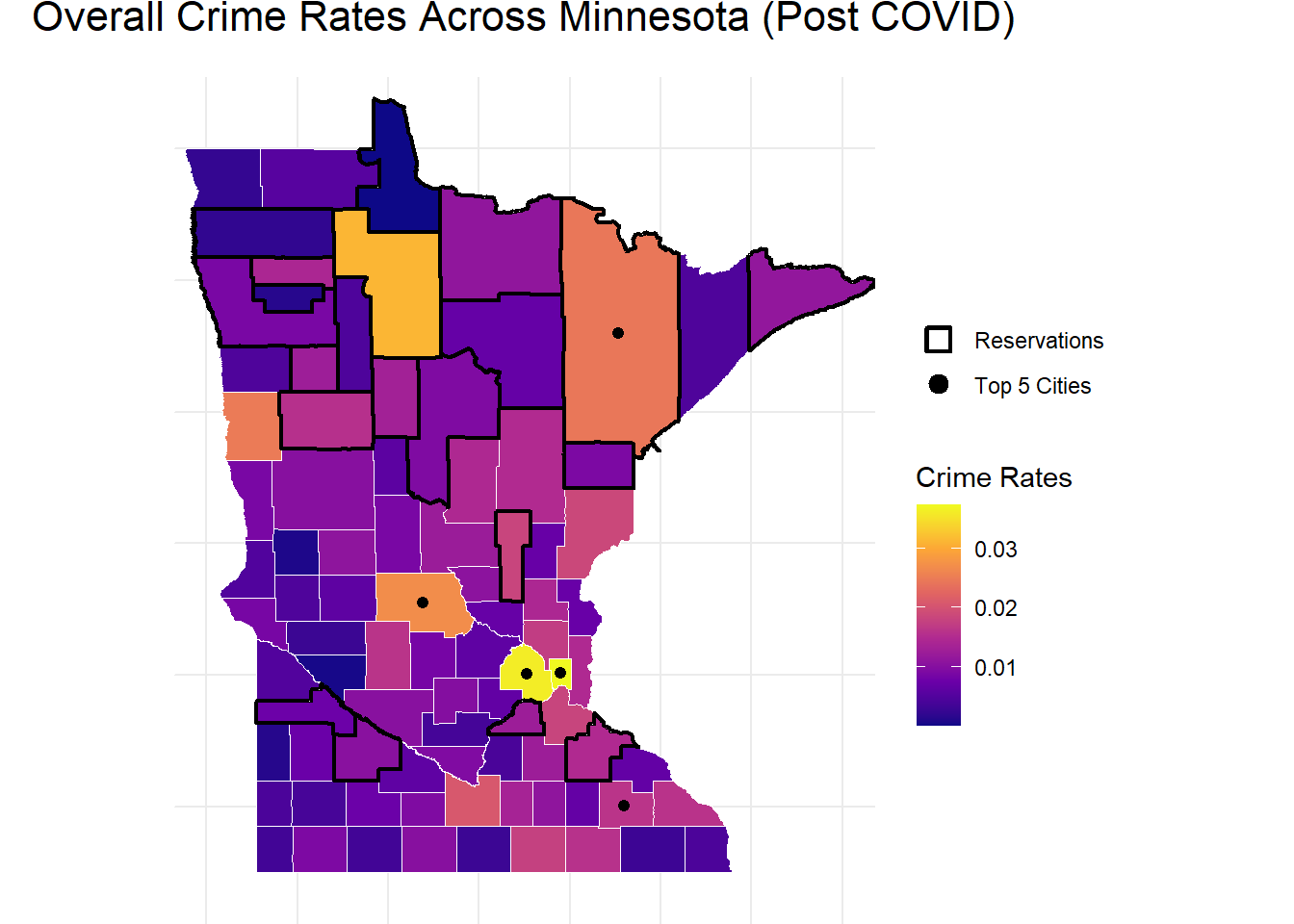
A spatial analysis of the post COVID five-year averages for crime rates per capita reveals distinct geographic patterns and highlights the relationship between population and large cities with crime. Higher crime rates are concentrated within major urban centers, with a noticeable decline in surrounding suburban areas. Outside of the Twin Cities region, other population hubs also exhibit above-average crime rates. One clear outlier is Beltrami County, which can be seen as a clear yellow county in the upper central portion of the crime rate map despite its lack of a high population.
This county is home to the Miskwaagamiiwi-Zaagaiganing, or the Red Lake Nation’s people. According to the Minnesota Indian Affairs Council, “Employment on the reservation is very limited, resulting in high unemployment rates” (Minnesota Indian Affairs Council, n.d.). This lack of employment potentially explains the relatively high crime rates seen in Beltrami County. Across the variables measured in this study, this could potentially showcase a relationship between variables such as median income and crime.
Pre-Modeling Relationship Analysis
| variable | mean_pre | mean_post | sd_pre | sd_post | p.value |
|---|---|---|---|---|---|
| median_household_income_acs5 | 61656.48276 | 77500.64368 | 11425.78664 | 12977.17976 | 0.00000 |
| pct_non_white | 9.01708 | 13.85626 | 7.57129 | 8.71725 | 0.00013 |
| pct_highschool_or_greater | 91.37000 | 92.51558 | 2.75060 | 2.38527 | 0.00380 |
| crime_rate | 0.01367 | 0.01055 | 0.00808 | 0.00736 | 0.00860 |
| pct_lessthan_5kincome | 4.54495 | 4.08114 | 1.30145 | 1.15803 | 0.01399 |
| per_capita_migration | 0.06175 | 0.05681 | 0.01718 | 0.01665 | 0.05592 |
| pct_young_males | 3.20551 | 3.36270 | 0.58305 | 0.58480 | 0.07759 |
| pct_children_missing_parents | 32.89281 | 32.57961 | 2.06612 | 2.63064 | 0.38376 |
| officers | 2.79728 | 2.71555 | 1.11009 | 0.65202 | 0.55471 |
| persons_per_household | 2.45877 | 2.45170 | 0.20076 | 0.16975 | 0.80233 |
| per_capita_alc_taxes | 16.41118 | 16.32717 | 7.45967 | 7.28797 | 0.94019 |
| persons_per_m2 | 0.00005 | 0.00005 | 0.00016 | 0.00016 | 0.95437 |
An examination of the predictive variables used in Norman & Arwood (1998) indicates no statistically significant changes at the 5% level between the pre and post-COVID periods for the per capita migration, percent young males, percent of children missing parents, officers per 1,000 residents, persons per household, per capita alcohol taxes, and persons per square meter. However, across the rest of the variables, we see relatively larger and more significant changes in crime rates, income, education, heterogeneity, and revenue from alcohol taxes.
| variable | estimate | estimate_1998 | p.value | p.value_1998 |
|---|---|---|---|---|
| persons_per_m2 | 0.4989 | 0.4533 | 0.000 | 0.001 |
| per_capita_migration | 0.4249 | 0.4809 | 0.000 | 0.001 |
| pct_non_white | 0.4095 | 0.4565 | 0.000 | 0.001 |
| per_capita_alc_taxes | 0.3033 | 0.5816 | 0.000 | 0.001 |
| persons_per_household | 0.2517 | 0.1184 | 0.001 | 0.275 |
| pct_highschool_or_greater | -0.1907 | 0.4999 | 0.012 | 0.001 |
| pct_young_males | 0.1832 | 0.3173 | 0.016 | 0.003 |
| pct_lessthan_5kincome | 0.1381 | -0.2707 | 0.069 | 0.011 |
| officers | 0.1084 | -0.4099 | 0.154 | 0.001 |
| pct_children_missing_parents | 0.0864 | 0.7392 | 0.257 | 0.001 |
| median_household_income_acs5 | -0.0067 | 0.2833 | 0.930 | 0.008 |
Further, correlation analyses show that many of the variables of interest exhibit reasonably strong and significant correlations with per capita crime. A large difference between this study and Norman and Arwood’s (1998) are the findings of persons per household being significant, while the previous study found no significant correlation, in addition to the lack of significance in the correlations with median household income, officers per 1,000 people, and the percent of children missing their parents. The insignificance of the percent of children missing their parents is also a noticeably large shift from their previous study, with a shift from .7392 to .0864 correlation. Additionally, the persons per household correlation change aligns with Boman and Gallupe’s 2020 study, suggesting that the more people are quarantined together, the more violence could occur.
Manual Variable Selection
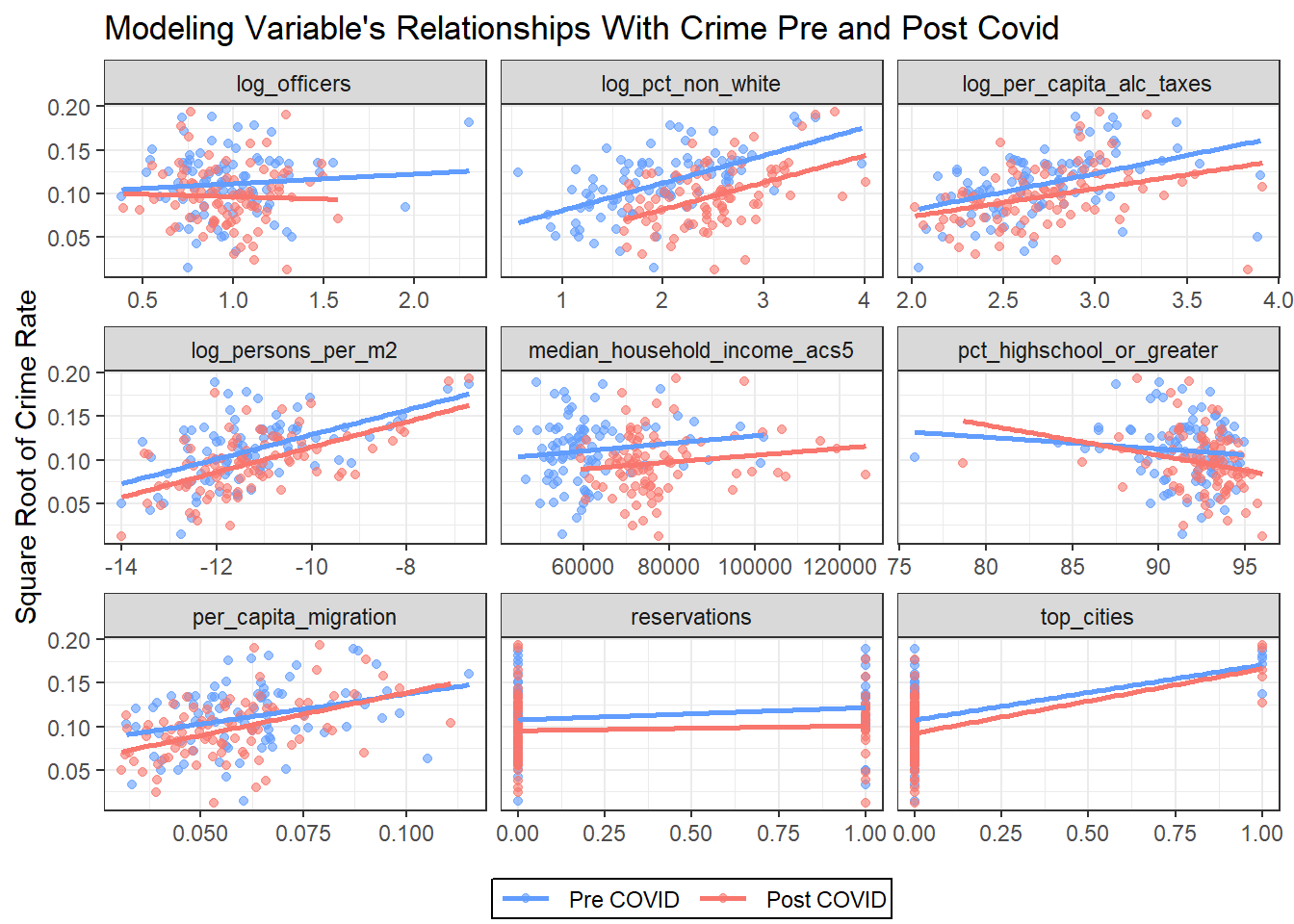
After fitting preliminary models, the percent of the children missing parents(pct_children_missing_parents), percent of young males(pct_young_males), and persons per household(persons_per_household) in a county were removed due to consistently high p-values (greater than 0.50) across model specifications. The variable percent of people in a county with less than $5000 income(pct_lessthan_5kincome) was also removed from the main regression models because of its strong negative correlation (−0.70) with median household income and because it represents a fixed dollar amount whose real value changes over time, making it an unstable measure in a time series context. Variables prefixed with log_ were transformed using the natural logarithm to stabilize variance and reduce the influence of extreme values often produced from the Twin Cities counties (Ramsey and Hennepin). The results of the transformed variables can be seen in the above plots.
Three additional features were also introduced to capture structural differences across counties: an indicator for whether a county contains a federally recognized reservation (reservations), an indicator for counties containing one of Minnesota’s five largest cities (top_cities; Ramsey, Hennepin, Olmsted, St. Louis, and Stearns), and a pre-/post-COVID indicator distinguishing observations from the 2019 (pre) and 2024 (post) ACS 5-year estimates. Together, these steps yielded a set of nine primary predictors used to explain variation in per-capita crime rates.
Across these predictors in the above plot, a potentially significant change in slope can be seen for the log of officers per 1,000 people(log_officers), the log of the per capita revenue from alcohol taxes(log_per_capita_alc_taxes), percent of people with a high school degree of greater(pct_highschool_or_greater), persons moved in to the county per capita(per_capita_migration), and the reservation and top cities indicator variables. Due to the plots above, their interactions with the pre and post COVID indicator will also be tested in subsequent regression models.
LASSO Estimation and Variable Selection
To further assess the validity of these variable selection decisions and to identify any potentially omitted predictors or interaction effects, a LASSO regression was fit using the full set of available variables and all interaction terms. This model provides an additional perspective on the relative importance of the full set of potential explanatory variables. Unlike other traditional regressions, which rely on statistical significance conditional on a specified model, the LASSO model penalizes coefficient size and shrinks less informative variables exactly to zero. As a result, variables that remain in the model and have estimated coefficients can be interpreted as those with the strongest predictive relationships with crime rates in a high-dimensional setting. Additionally, as the LASSO model relies on normalized predictor values, all of the magnitudes of the coefficients can be directly compared and interpreted as variable importance. These factors make it a useful tool in variable selection, as all unimportant variables will have their coefficients set to 0 or near 0 and dropped automatically.
LASSO Regression is defined as:
\[
min_\beta \left(\sum^n_{i=1}(y_i-\hat{y}_i)^2 + \lambda\sum^p_{j=1} |\beta_j|\right)
\] Where:
\(y_i\) = the observed response value
\(\hat{y}_i\) = the predicted response value
\(\beta_j\) = the regression coefficient for predictor j
\(\lambda\) = the regularization parameter determining the strength of the penalty
\(p\) = the number of parameters
Formally, the LASSO estimation solves the optimization problem in which the sum of squared residuals is minimized subject to an L1 penalty on the absolute values of the regression coefficients. This penalty introduces a bias–variance tradeoff to ordinary least squares by shrinking coefficient estimates toward zero in exchange for lower variance and improved predictive performance. The L1 penalty is particularly important because, unlike in ridge regression, the absolute value of \(\beta_j\) allows the model to set some of the predictors to 0 rather than merely shrinking their coefficients. The strength of the regularization parameter \(\lambda\) is chosen via 10-fold cross-validation, balancing model fit against complexity. In this setting, LASSO is especially well suited for evaluating a large number of correlated socioeconomic predictors and interaction terms, where traditional OLS estimation suffers from collinearity and overfitting (Fonti & Belitser, 2017).
| s0 | |
|---|---|
| reservations:per_capita_migration | 0.3983581 |
| (Intercept) | 0.3308518 |
| log_persons_per_m2 | 0.0120664 |
| log_per_capita_alc_taxes:per_capita_migration | 0.0107359 |
| post_covid:per_capita_migration | 0.0087332 |
| log_officers | 0.0050688 |
| log_per_capita_alc_taxes:pct_lessthan_5kincome | 0.0021887 |
| reservations:log_pct_non_white | 0.0019057 |
| pct_young_males:log_officers | 0.0012845 |
| pct_lessthan_5kincome:reservations | 0.0011212 |
| pct_lessthan_5kincome:log_persons_per_m2 | 0.0007777 |
| persons_per_household:log_persons_per_m2 | 0.0004397 |
| pct_lessthan_5kincome:log_pct_non_white | 0.0002162 |
| pct_young_males:log_persons_per_m2 | 0.0001436 |
| pct_children_missing_parents:log_pct_non_white | 0.0001369 |
| post_covid:reservations | -0.0035877 |
The LASSO results indicate that interactions involving population density, migration, alcohol taxation, and reservation status retain the largest non-zero coefficients. In particular, the interaction between reservations and per_capita_migration emerges as the most influential predictor, suggesting that migration is strongly associated with crime rates in counties containing reservations. Several additional interaction terms involving population density (persons_per_m2), household size, alcohol tax revenue, and policing levels also have non-zero coefficients, demonstrating the potential importance of population density and economic factors in explaining crime variation.
Overall, the LASSO model supports the primary modeling strategy by confirming that population density, migration, alcohol-related revenue, reservation status, and urban density contain the most information for explaining county-level crime, while many alternative demographic measures contribute little additional explanatory power in a high-dimensional setting.
Despite the many interaction terms found to be meaningful by the LASSO model, the interaction between reservation status and per-capita net migration was the only one to remain stable across OLS specifications. The relationship between migration and crime is approximately linear within both reservation and non-reservation counties, and no transformation was required to achieve linearity or variance stabilization. This interaction also has a comparatively large coefficient in the LASSO model, supporting its relevance. As a result, the reservation-migration interaction term was retained in the final model as a meaningful effect.
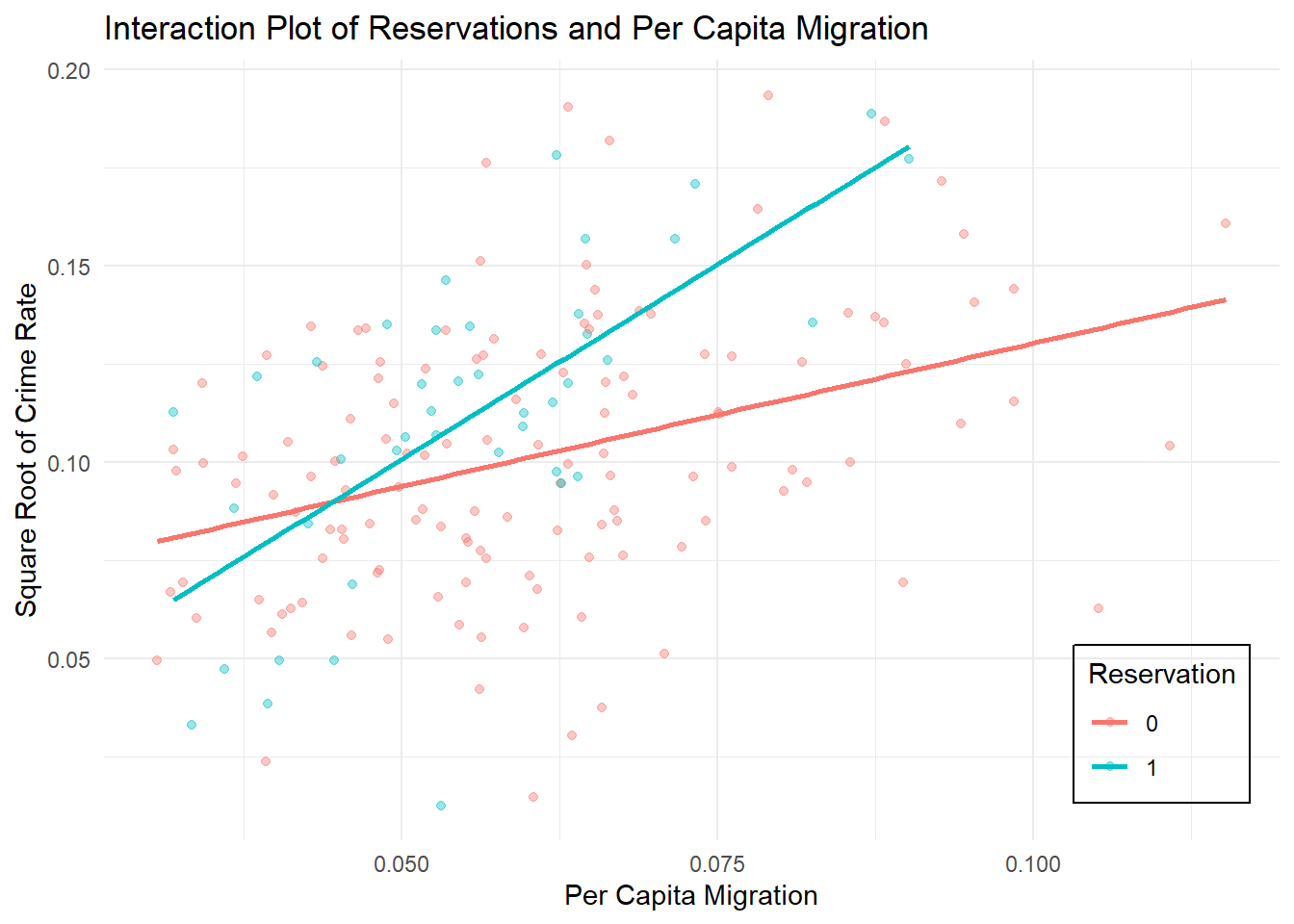
While migration may plausibly proxy for population turnover or density-related processes, including additional interaction terms between migration and population density (persons_per_m2), racial composition (pct_non_white), median household income, and alcohol tax revenue, it does not change the estimated reservation–migration interaction. In those models, the migration interaction with other terms remains statistically insignificant, while the reservation interaction retains both its magnitude and statistical significance.
This interaction implies that compared to counties without reservations, increases in net migration are associated with higher crime rates in counties containing reservations. These different slopes suggest that migration operates through distinct mechanisms in reservation counties, potentially reflecting differences in housing availability, available jobs, or access to social services. While the analysis does not identify a causal mechanism, the significance of this interaction after controlling for other economic conditions, population density, racial composition, and alcohol-related revenue indicates that reservation status meaningfully moderates the relationship between migration and crime.
OLS Estimation
Fitting the model defined as:
\[ \begin{aligned} \sqrt{crime\_rate_i} &= \hat{\beta}_0 + \hat{\beta}_1 \, median\_household\_income_i + \hat{\beta}_2 \, \log(persons\_per\_m^{2}_i) \\ &\quad + \hat{\beta}_3 \, reservations_i + \hat{\beta}_4 \, (reservations_i \, per\_capita\_migration_i) \\ &\quad + \hat{\beta}_5 \, \log(pct\_non\_white_i) + \hat{\beta}_6 \, \log(per\_capita\_alc\_taxes_i) + \varepsilon_i \end{aligned} \]
Produces the following results
| term | estimate | std.error_normal | std.error_robust | p.value |
|---|---|---|---|---|
| (Intercept) | 0.3460412 | 0.031 | 0.046 | 0.000 |
| median_household_income_acs5 | -0.0000013 | 0.000 | 0.000 | 0.000 |
| log_persons_per_m2 | 0.0204319 | 0.002 | 0.002 | 0.000 |
| reservations:per_capita_migration | 1.2950588 | 0.251 | 0.274 | 0.000 |
| reservations | -0.0571894 | 0.015 | 0.017 | 0.001 |
| log_pct_non_white | 0.0089669 | 0.003 | 0.003 | 0.005 |
| log_per_capita_alc_taxes | 0.0197153 | 0.005 | 0.008 | 0.012 |
The above regression results reveal several robust relationships between county-level crime rates and key socioeconomic and spatial predictors. Median household income is negatively associated with crime, consistent with prior literature, while population density (measured as the log of persons per square meter), per-capita alcohol tax revenue, and the proportion of non-white residents are all positively associated with higher crime rates. Counties containing reservations exhibit significantly lower baseline crime rates on average; however, this effect is strongly moderated by net migration, as reflected in the large and highly significant interaction between reservation status and per-capita migration.
A large concern with county-level ACS data is the presence of both spatial and temporal autocorrelation, which can lead to downward-biased standard errors and overly generous p-values under OLS assumptions. To partially address this issue, the model is estimated using standard errors that are robust to clustering across the same counties. Both classical and clustering-robust (CR2) standard errors are reported for comparison; inference is also based on these cluster-robust estimators. Multiple clustering and heteroskedastic corrections were tried, including CR1 (Liang–Zeger), CR2, and HC3. Across all three approaches, the key coefficients, particularly the reservation-by-migration interaction, remain statistically significant. As stated by Alberto Abadie et al. (2017), clustering errors are largely overly conservative; CR2 standard errors are still reported here, as in this case, they don’t impact the significance of the chosen predictors heavily and provide reasonable increases in standard errors while avoiding the excessive corrections of CR3.
Several variables and interaction terms examined in earlier specifications, including policing levels, urban-county indicators, educational attainment, and all COVID interactions, were excluded from the final model due to consistent insignificance once robust inference was applied. Notably, the post-COVID indicator itself does not significantly alter the relationships between crime and its predictors, suggesting that while crime rates increased during the pandemic period, the structural relationships between crime and traditional sociological factors remained largely the same.
| R2 | Adj_R2 | RMSE |
|---|---|---|
| 0.662 | 0.65 | 0.021 |
This model explains approximately 66.2% of the variation in county-level crime rates and achieves a root mean squared error (RMSE) that is roughly half the standard deviation of observed crime rates, indicating a strong overall fit. Also, the adjusted R2 remains close to the unadjusted R2, suggesting that the model is not overfitting and that the included predictors contribute meaningfully to explaining variation in crime rates.
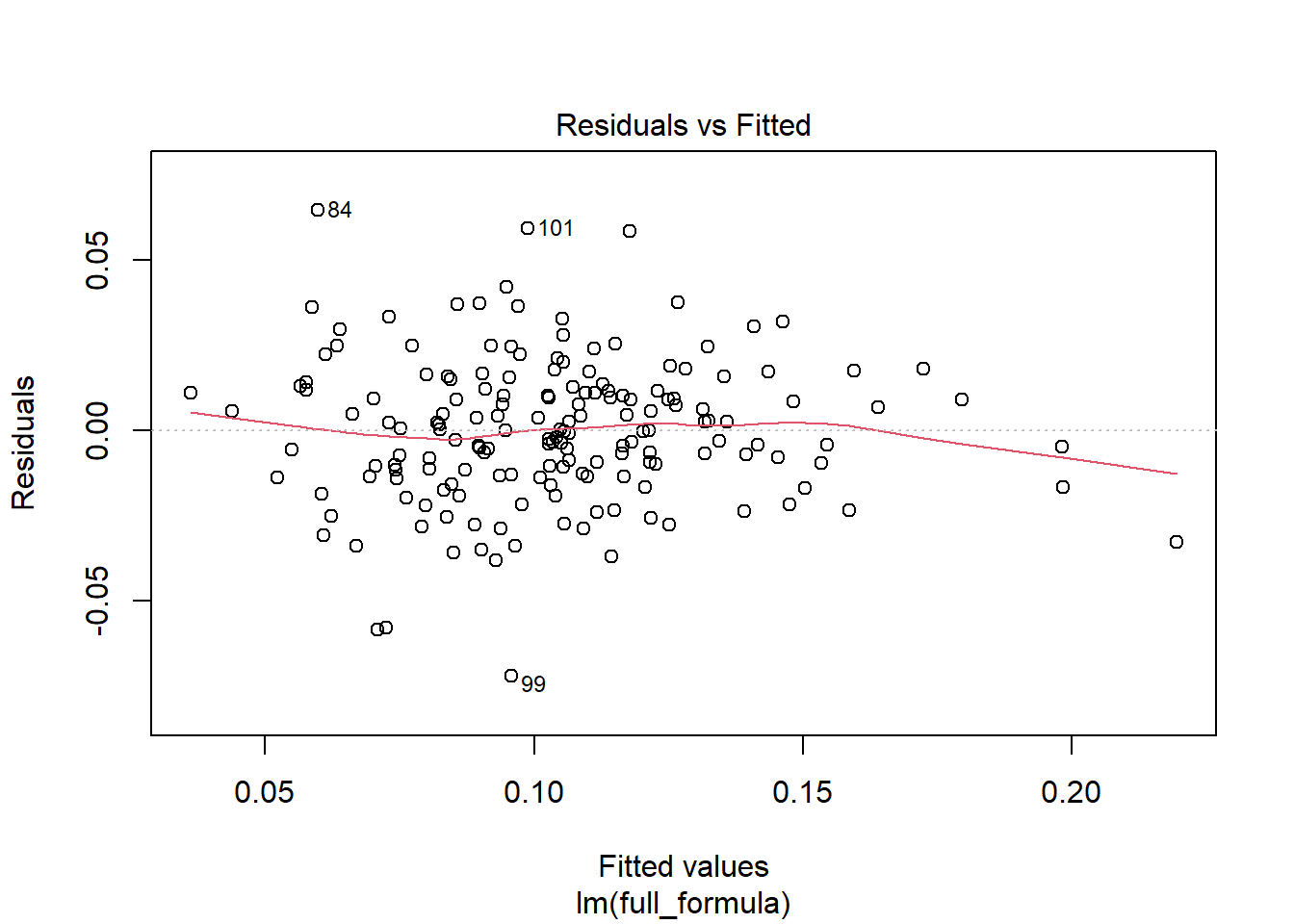
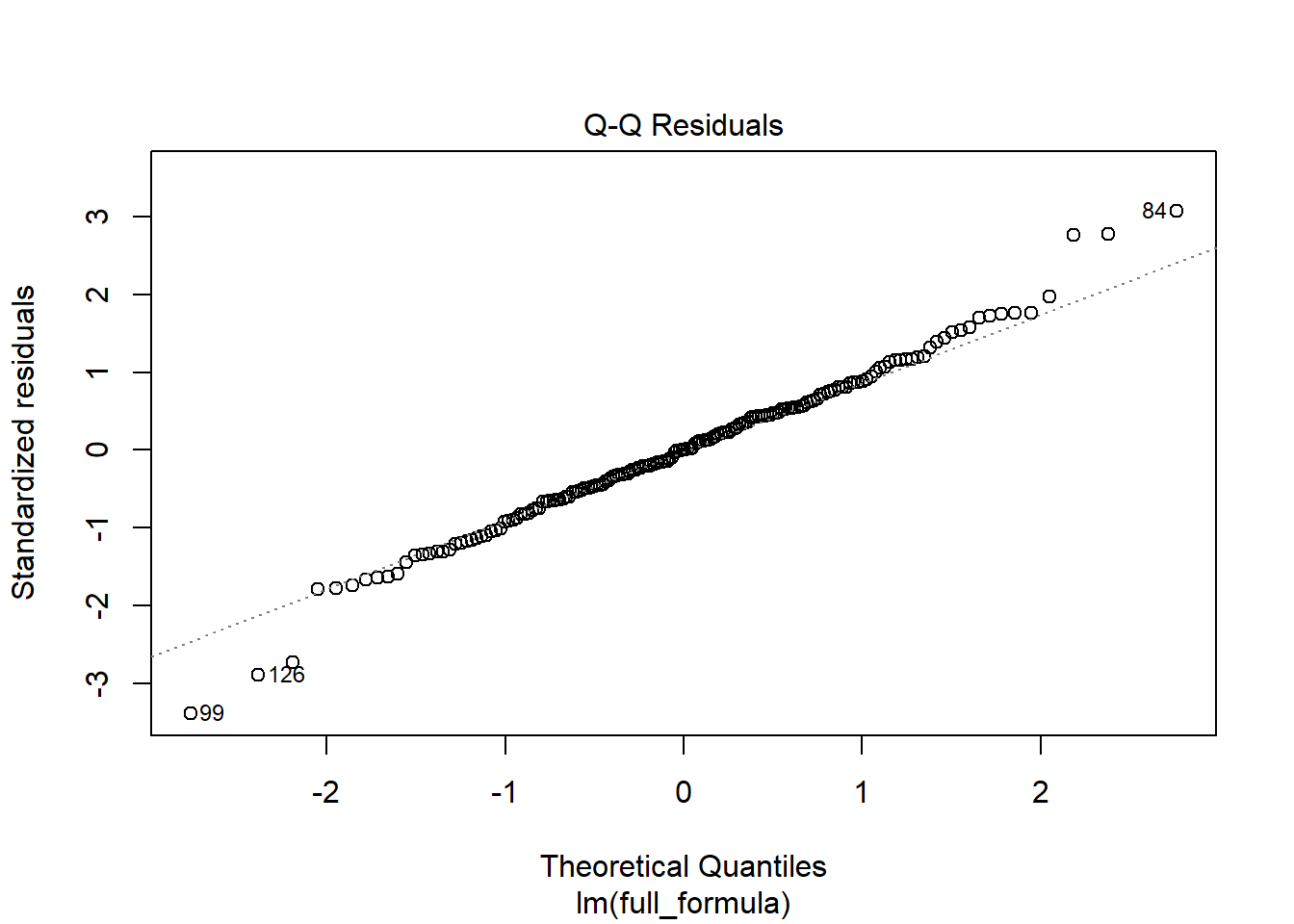
As seen below, the residuals are approximately centered at 0 with no obvious outliers or patterns, further demonstrating the validity of an OLS approach to this data.
Shapiro-Wilk normality test
data: total_model$residuals
W = 0.98868, p-value = 0.1787 Additionally, as can be seen above, the model also satisfies its normality in the residuals assumption, failing to reject the null hypothesis of the Shapiro-Wilk normality test that the residuals are normally distributed, at a .17 level. Furthermore, as can be seen below, the majority of residuals match up with the normal distribution, barring small deviations at the tails. However, on both upper and lower tails, there is some drift above and below the theoretical normal distribution, which is contained in only 6 points and not enough to impact the conclusions from this model meaningfully.
OLS Interpretations
The linear model reveals a limited set of robust predictors of county-level crime, with many traditional sociological variables losing explanatory power once controls and interaction terms are included. As in Norman and Arwood’s previous work, only a small subset of variables remain statistically significant at conventional levels, and all interaction terms with the post-COVID indicator are not statistically distinguishable from zero.
The first notable finding concerns median household income, which exhibits a negative relationship with per-capita crime rates. The coefficient on median_household_income_acs5 (-0.0000013) implies that a $10,000 increase in median household income is associated with a reduction of approximately 0.169 crimes per 1,000 residents on average, holding all else constant. While modest, this effect is precisely estimated and highly significant, suggesting that higher-income counties consistently experience lower crime rates, controlling for density, demographics, and other covariates. This aligns with Norman and Arwood’s earlier findings that economic deprivation is associated with higher crime, supporting the conclusion that economic conditions remain a meaningful determinant.
Population density emerges as a stable predictor but is modest in its effects on crime. The log of persons per square meter is positive and highly significant with a coefficient of 0.0204, implying that for every additional 10% increase in population density, you would expect an average increase of 0.0042 crimes per 1,000 people, holding all else constant. This finding strengthens the evidence relative to Norman and Arwood’s earlier work, where population density was only marginally significant, and suggests that urban density is a key structural factor in crime.
The reservation indicator and its interaction with per-capita net migration are both highly significant. Counties with a reservation have slightly lower baseline crime rates (−0.057) on the square root scale, but the reservation-migration interaction is substantially larger (1.29). This implies that for every additional migration per 1,000 people into a reservation county is associated with roughly 0.00129 additional Part 1 index crimes per resident, whereas migration has a negligible impact in non-reservation counties. This interaction is robust to transformations, outlier removal, and cluster-robust standard errors, demonstrating that migration effects on crime are context-dependent and particularly pronounced in counties containing reservations. This stability suggests that the observed relationship reflects long-standing structural and institutional factors and not pandemic-related disruptions. Another potential reason for this can be seen in the FBI’s handling of crimes committed on tribal land (Federal Bureau of Investigation, n.d.). The majority of crimes used in the operationalization of crime rates are included under the ‘serious’ offenses, which, if committed on tribal land, are automatically handled by the FBI, bypassing the potential source of under-reporting from the police to the FBI.
The log of the percent of non-white residents is positive (0.009) but with only a very marginal effect; a 10% increase in the percent non-white population is associated with approximately 0.0008 additional crimes per 1,000 residents. This suggests that racial heterogeneity, while correlated with crime in simpler models, does not independently explain variation once density, income, and other controls are included. As stated in prior work, this relationship likely reflects broader geographic and socioeconomic clustering rather than a direct causal mechanism.
Similarly, per-capita alcohol tax revenue (log_per_capita_alc_taxes) is positive but modest (0.0197): a 10% increase in per-capita alcohol tax revenue is associated with approximately 0.004 additional crimes per 1,000 residents. Educational attainment (percentage with a high school degree or greater) is not significant, suggesting that education primarily proxies for density, urbanization, and median income rather than exerting a direct effect on crime.
Variables capturing large city status, police presence, and migration alone are not significant after controls are included. Their estimated impacts in original units are close to zero, further highlighting that migration effects in non-reservation counties are minimal. The inclusion of the reservation × migration interaction explains most of the predictive variation previously attributed to migration, underscoring the importance of context-dependent relationships for these variables.
Finally, the post-COVID indicator itself is highly statistically insignificant and removed from the model, suggesting that once demographic and economic factors are accounted for, there is no clear evidence of a structural shift in the relationship between crime and its traditional predictors following the pandemic, even if previous plots have shown some evidence of its effects. The insignificance of nearly all interaction terms reinforces this conclusion, indicating that COVID-19 did not structurally alter how socioeconomic characteristics relate to crime across counties.
Structural Break Tests
This interpretation is further supported by the structural break tests presented below, which fail to detect meaningful parameter instability over time. In order to test for significant changes in the relationships between crime and its predictors and in crime rates themselves, two complementary tests are used: the Chow (M-fluctuation) test and the CUSUM test. The Chow test explicitly evaluates whether the regression coefficients differ across a predefined breakpoint (Zeileis, 2002), in this case, the onset of the COVID-19 period. It tests the null hypothesis that the residuals from fitting a model estimated over the full data do not differ significantly from those obtained by estimating separate models before and after the breakpoint. If this test rejects the null hypothesis, it would indicate a need for different estimates before and after COVID, which would signify a change in the relationships between crime and its determinants during this time.
The CUSUM test provides an assessment of parameter stability by examining the cumulative sum of recursive residuals over time. Rather than testing for a break at a single known point, the CUSUM test detects gradual or unknown structural changes by identifying whether the cumulative sum of the standardized residuals drifts outside their confidence bounds defined by standard Brownian motion (Zeileis, 2002). If the null hypothesis of this test is rejected, it would suggest that during the modeling of crime, there is a point at which the mean of the residuals differs from 0, and a separate model should be fit to explain this variance.
Chow test (post-COVID breakpoint)
M-fluctuation test
data: total_model
f(efp) = 1.2684, p-value = 0.4426CUSUM test
OLS-based CUSUM test
data: cumsum_process
S0 = 0.78581, p-value = 0.5674 The result of the Chow test is a failure to reject the null hypothesis, indicating no statistically significant structural change in the estimated coefficients following the onset of COVID. Additionally, the CUSUM statistics remain well within the critical boundaries throughout the sample period, even during the shift from pre to post COVID, suggesting stable regression parameters over this period. This is seen in the failure to reject the null hypothesis that the variance in the estimated parameters is stable over time.
Together, these results provide strong evidence that the underlying relationship between crime and its sociological determinants has remained largely unchanged, even in the presence of the substantial social and economic disruption caused by the COVID-19 pandemic. While crime levels themselves may have temporarily increased, the structural form of the model and the influence of key explanatory variables appear to be stable over time, reinforcing the conclusion that COVID did not fundamentally alter the mechanisms linking crime to its traditional predictors.
Differenced Model Estimation
A model is now fit using the difference between pre and post-COVID to see if any of the changes in explanatory variables are associated with a change in crime rates across COVID. Using this approach, the only variables found to have a statistically significant relationship at the < .05 level on the change in crime rates is change in the population density measured in m2, as well as the change in the heterogeneity of the population. The negative coefficient suggests that counties experiencing increases in population density over this period tended to see relative declines in crime rates, while counties with decreasing density experienced relative increases. The significance of the percent non-white in this case seems to be a type 1 error, especially due to its high lack of significance in other models. No other changes in variables were found to be statistically significant predictors of changes in crime rates, indicating that much of the observed variation in crime across counties during this period is not explained by concurrent changes in these factors.
Fitting the model of these differences defined as: \[
\begin{aligned}
{crime\_rate\_post} - {crime\_rate\_pre}
&= \hat{\beta}_0
+ \hat{\beta}_1 \, (\log(persons\_per\_m2\_post) - \log(persons\_per\_m2\_pre)) + \\
&\quad \hat{\beta}_2 \, (\log(pct\_non\_white\_post) - \log(pct\_non\_white\_pre)) + \varepsilon
\end{aligned}
\]
Produces the following results
| term | estimate | std.error | p.value |
|---|---|---|---|
| Difference Model | |||
| (Intercept) | -0.0041746 | 0.001 | 0.000 |
| log_persons_per_m2_diff | -0.0269598 | 0.011 | 0.016 |
| log_pct_non_white_diff | 0.0029922 | 0.001 | 0.024 |
Examining the metrics of this differenced model, as well as a LASSO regression model, similar results are shown. The extremely low R2 shows again that none of the considered factors are explaining much of the actual variance in changes of crime rates before and after COVID.
| R2 | Adj_R2 | RMSE |
|---|---|---|
| 0.124 | 0.103 | 0.003 |
The differenced LASSO model also only selects the population density measure and the percent non-white. The two variables are estimated again with coefficients in the same direction showing them as the only potentially meaningful predictors among these traditional sociological factors for explaining the changes in crime rates over COVID. Again, the coefficient for percent non-white remains much lower than for population density, further showcasing its potential invalidity as a predictor of crime.
| s0 | |
|---|---|
| log_pct_non_white_diff | 0.0019499 |
| (Intercept) | -0.0040644 |
| log_persons_per_m2_diff | -0.0127796 |
Conclusions
This study has revisited and extended the county-level framework of Norman and Arwood to ask whether COVID changed the relationships between county sociological characteristics and Part 1 crime in Minnesota. This study was conducted using five-year ACS averages (2015–2019 vs. 2020–2024) and aggregated crime counts from the FBI. From this data, some key takeaways have become clear.
Firstly, median household income is robustly and negatively associated with county crime rates: wealthier counties have lower crime, holding other controls constant. Population density is also a stable, positive predictor of higher crime. These results stem from OLS regression with robust standard errors, as well as LASSO penalization, and together account for a large proportion of cross-county variations in crime rates.
Secondly, the reservation-per-capita migration interaction emerges as a highly significant and substantively meaningful predictor. While migration alone does not systematically affect crime across all counties, increases in net migration are associated with disproportionately higher crime in counties containing reservations, even after controlling for income, density, racial composition, and alcohol-tax revenue. This interaction is robust across specifications and transformations, highlighting a context-dependent pathway for crime variation that was not captured in earlier studies due to the lack of a reservation indicator variable.
Thirdly, the post-COVID indicator and its interaction terms remain statistically insignificant, and structural-break tests detect no meaningful changes in parameter relationships across the two periods. Although crime rates fluctuated during the pandemic, these fluctuations are not explained by changes in the main sociological predictors, indicating resilience in the structural determinants of county-level crime.
Fourthly, other variables such as education, racial composition, per-capita police officers, migration alone, and alcohol-tax revenue show only weak or conditional effects once income, density, urban indicators, and reservation status are included. The LASSO model reinforces this conclusion, retaining a small subset of variables (density, migration, alcohol revenue, racial composition, reservation and urban indicators, and income) as carrying most of the predictive information. In models of differenced crime rates (post minus pre), almost none of the observed changes in these sociological variables explain the variation, with population density change as the sole consistent and reliable predictor—but with a small negative coefficient, suggesting that counties experiencing small density increases tended to see relative decreases in crime.
Overall, these findings suggest that economic standing, urban density, and the interaction between migration and reservation status are the most robust determinants of county-level crime in Minnesota. While the pandemic produced short-term fluctuations in crime, the structural relationships between crime and these key predictors remained largely stable. These results reinforce the importance of accounting for both contextual heterogeneity (such as reservations) and spatially correlated factors when modeling crime at the county level, while also highlighting the limitations of standard ACS variables for explaining short-term changes in crime.
Limitations and Future Work
These crime counts come from the Federal Bureau of Investigation (FBI) and inherit known reporting limitations (underreporting, changes in definitions and agency reporting practices, variation across local agencies). For one, jurisdictional and tribal-land reporting differences can affect counts for reservation counties (the FBI’s handling of serious offenses on tribal lands differs from municipal reporting), which complicates direct comparison across counties.
Furthermore, many of the sociological predictors are five-year ACS averages reported by the U.S. Census Bureau (due to it being the most granular level at which every Minnesota county is reported); these smooth short-term dynamics and carry sampling/response errors, as well as being estimates rather than true values.
For future work, I would recommend a variety of continuations, namely: spatial econometric approaches that explicitly model correlations between neighboring counties, and use yearly (not five-year averaged) data where available. Also, analyses at finer geographic units would be much more relevant as crime does not occur on county levels but at smaller spatial scales (e.g., neighborhoods, census tracts, or blocks). Further, the incorporation of new indicators (housing instability, unemployment, and mobility, among others) as well as administrative data about police reporting practices would allow for better controls of potentially spurious correlations in this model and could reveal new insights. Finally, careful treatment of tribal jurisdiction issues is required to better understand the reservation results.
Final Summary
Overall, the pandemic produced a noticeable, short-lived rise in some serious offenses, but did not fundamentally reshape the cross-county relationships between serious crime and a county’s socioeconomic and spatial characteristics. Income inequality and urban density remain the dominant and stable predictors of county-level crime in Minnesota. Many of the commonly discussed sociological measures explain little additional cross-county variation once these structural factors are accounted for. However, the impact of migration into reservation counties emerged as a very meaningful factor in predicting crime and builds on the previous studies’ findings showing that crime across Minnesota counties needs to account for the impact of tribal land and migration into it.
References
Fonti, V., & Belitser, E. (2017). Feature selection using lasso. VU Amsterdam Research Paper in Business Analytics, 30, 1–25.
James, N., & Logan, R. (2008). How crime in the united states is measured. Congressional Research Service. https://apps.dtic.mil/sti/html/tr/ADA476144/
Minnesota Department of Health. (n.d.). Alcohol use among youth in minnesota. Retrieved https://www.health.state.mn.us/communities/alcohol/documents/youthalcoholuse.pdf
Minnesota Department of Revenue. (n.d.). Sales and use tax statistics for liquor sales and 2.5% tax by county. Retrieved https://www.revenue.state.mn.us/sales-and-use-tax-statistics-and-annual-reports
Minnesota Indian Affairs Council. (n.d.). Red lake reservation - miskwaagamiiwi-zaagaiganing (red lake nation). Retrieved https://mn.gov/indian-affairs/tribal-nations-in-minnesota/miskwaagamiiwi-zaagaiganing-red-lake-nation.jsp
National Law Enforcement Telecommunications System. (1981). ORI (originating agency identifier) directory. U.S. Department of Justice.
Norman, J. M., & Arwood, D. E. (1998). A social disorganization theory of county crime rates in minnesota. Great Plains Sociologist, 11(2), Article 2. https://openprairie.sdstate.edu/greatplainssociologist/vol11/iss2/2
Substance Abuse and Mental Health Services Administration. (2025). Key substance use and mental health indicators in the united states: Results from the 2024 national survey on drug use and health. Center for Behavioral Health Statistics; Quality. https://www.samhsa.gov/data/sites/default/files/reports/rpt56287/2024-nsduh-annual-national-report.pdf
U.S. Census Bureau. (2025). Comparing ACS data. https://www.census.gov/programs-surveys/acs/guidance/comparing-acs-data.html
William Borer Seabloom. (2026). Econometrics: Main project repository. https://github.com/lborerseabloom/Econometrics.git.